Llega el momento de pensar dónde y cómo almacenar las celdas en memoria. La forma en la que vamos a hacerlo es la siguiente. Usaremos un std::deque para reservar memoria. Los
deques permiten ir añadiendo memoria conforme se necesite y no mueven los bloques de memoria una vez reservados.
De todas las celdas que hayamos reservado, usaremos unas y tendremos otras libres, sin usar. Utilizaremos la recolección de basura para pasar celdas antes usadas pero ahora ociosas a celdas sin usar y libres para su reciclado.
La recolección de basura es un procedimiento que puede ser o bien muy complejo o bien muy simple. En este caso, y teniendo en cuenta que miniSL intenta implementarlo todo de la forma más simple y reducida, nos inclinaremos por el algoritmo más simple de recolección de basura. El llamado
mark and sweep (marca y barre).
El mark and sweep funciona en dos pasos. El primer paso detecta las celdas en uso. ¿Cómo hace eso? Muy simple. O bien es una celda raíz (que siempre está en uso) o bien nos referencian desde otra celda en uso. Estas celdas en uso son marcadas. El segundo paso es barrer (=reciclar) todas las celdas que no están marcadas y limpiar la marca en las que sí.
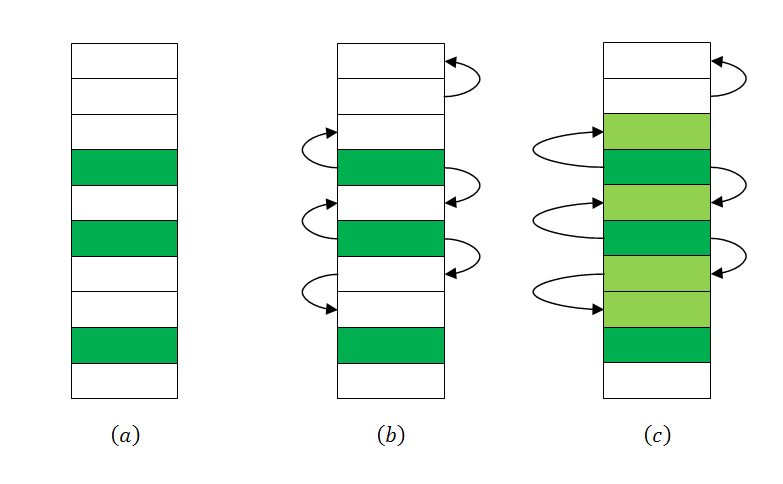
La siguiente figura muestra a) el conjunto raíz, b) los punteros entre celdas y c) las marcas. Las celdas que en c) no estén marcadas (las blancas) serán las reclamadas por el recolector de basura y pasarán a estar libres para un posterior uso.
En la implementación lo primero que tenemos es el std::deque de almacenamiento de celdas.
CELL_STORAGE m_Cells;
Recordemos que definíamos CELL_STORAGE así:
typedef std::deque<CELL> CELL_STORAGE;
También necesitamos saber si hay celdas libres. Las pondremos todas en una lista simplemente enlazada que empieza en el campo m_FirstUnused.
CELL* m_FirstUnused;
Para reservar una celda primero vemos si hay alguna libre. Si no, aumentamos el std::deque reservando memoria para una celda más. Esto no es muy económico ya que lo interesante habría sido devolver la memoria usada por las celdas libres. Estamos actuando más bien como un
pool que como un gestor de memoria.
CELL& Script::CreateCell(CELL_TYPE ct, CELL* first, CELL* second)
{
CELL* p;
if(m_FirstUnused==NULL)
{
CELL c;
m_Cells.push_back(c);
p=&m_Cells.back();
}
else
{
p=m_FirstUnused;
m_FirstUnused=p->next_unused;
}
p->mark=false;
p->type=ct;
p->head=first;
p->tail=second;
return *p;
}
El algoritmo de marcado es recursivo de manera que explora todo el grafo de referencias (punteros entre celdas) en profundidad. Dependiendo del tipo de celda, alguno o ninguno de sus campos serán referencias que hay que explorar. Evitamos los posibles ciclos no volviendo a marcar las celdas ya marcadas.
void Script::GCMark(CELL* c)
{
if(c==NULL || c->mark)
return;
c->mark=true;
switch(c->type)
{
case UNUSED: throw L"Marking unused cell";
case CONS_CTOR: GCMark(c->head); GCMark(c->tail); break;
case LAMBDA_VAL: GCMark(c->code); GCMark(c->closure); break;
case COMBINE_CODE: GCMark(c->op); GCMark(c->operands); break;
case ENVIR_VAL:
GCMark(c->parent_envir);
for(ENVIR_TABLE::const_iterator i=c->envir_table->begin(); i!=c->envir_table->end(); ++i)
{
GCMark(i->first);
GCMark(i->second);
}
break;
}
}
El caso más laborioso es el de los entornos. En ellos hay que iterar su contenido y explorarlo para el marcado.
El borrado ocurre en la rutina de barrido. Es simple y su única dificultad radica en las celdas especiales que contienen algún dato externo. Ya vimos uno de estos casos en las cadenas internas. Las cadenas normales y los entornos son otros casos similares. Cada uno de ellos ha de tener un borrado específico.
int Script::GCSweep()
{
int count=0;
for(CELL_STORAGE::iterator i=m_Cells.begin(); i!=m_Cells.end(); ++i)
{
if(i->mark)
{
i->mark=false;
continue;
}
if(i->type==UNUSED)
continue;
++count;
switch(i->type)
{
case STRING_LIT: delete i->string_val; break;
case ENVIR_VAL: delete i->envir_table; break;
case NAME_CODE: m_InternedStrings.erase(*i->string_val); break;
}
i->type=UNUSED;
i->next_unused=m_FirstUnused;
m_FirstUnused=&*i;
}
return count;
}
Como conjunto raíz vamos a tener únicamente el entorno global. Añadimos una referencia a la celda de entorno de que lo contenga y lo marcamos en la recolección de basura.
int Script::GarbageCollect()
{
GCMark(m_GlobalEnvir);
return GCSweep();
}
A partir de aquí hemos de recordar que el entorno global es una celda destacada. De hecho, estará referenciada en la clase Script.
CELL* m_GlobalEnvir;
El lector atento habrá visto que hemos retornado el número de celdas barridas en el recolector de basura. El retorno del número de celdas es un buen sistema para depurar el recolector de basura, pero no es el único. De hecho, nos ofrece poca información. Otro sistema que va a ser útil no sólo para el recolector de basura sino también para observar los resultados de las evaluaciones es la impresión de celdas. En la siguiente entrada nos dedicaremos a esta tarea.