Los patrones de diseño no son más que una manera conocida de resolver problemas. Incluso sin saber lo que son, es probable que cualquier programador los haya usado sin querer. Esto es así porque muchas veces son la solución más lógica y no dependen del lenguaje de programación que se use.
El patrón decorador se basa en el siguiente problema. Tengo una clase C y por alguna razón no puedo o no quiero tocarla, pero tendría que hacer algo que no hace. Es más, esta nueva funcionalidad ni siquiera necesita que modifiquemos su interfaz I (por lo que los usuarios de la clase ni se van a enterar que estoy modificando la funcionalidad por debajo).
La solución que propone el patrón decorador es crear otra clase D que implemente esta interfaz y que envuelva a la clase C. Cuando ejecutamos los miembros del interfaz de D, hacemos lo que tengamos que hacer como si fuéramos la clase C y, si fuera necesario, usamos la clase C que envolvemos. Es decir, suplantamos la clase C.
Ya está. Fácil, ¿no? Bueno, podemos refinar porque aún tenemos algunos problemillas. Si quiero agregar varias funcionalidades a C tendría que hacer una clase D1, D2..., pero también la que combina ambas cosas D12 (Imaginemos que C es un texto y las D son el tipo de letra. Entonces D1 sería "negrita", D2 sería "cursiva" y D12 "negrita y cursiva"). Si tuviera D1, D2, D3, D4... las combinaciones serían muchas. Es lo que se denomina una explosión exponencial.
Afortunadamente, la clase D puede envolver en vez de una clase C, una clase de interfaz I. Esto incluye otras clases D. En este caso, si escribo que D envuelve a C así D(C), la modificación D12 sería D1(D2(C)). Esto me evita tener que escribir clases compuestas D12, D24, etc y evito la explosión exponencial.
Por último, y para seguir la ley DRY, es conveniente que todas las clases D1, D2... deriven de una clase D común de "envoltura básica". Esto nos lleva al esquema usual del patrón decorador tal y como viene en la Wikipedia.
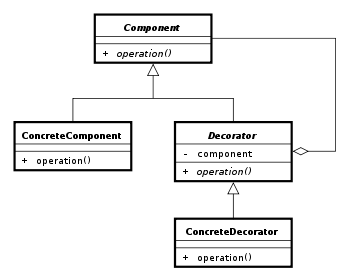
Donde
- "Component" es la interfaz común I.
- "ConcreteComponent" es la clase C que queremos modificar pero no tocar.
- "Decorator" es la clase base D de otros decoradores D1, D2... Esta clase lo único que hace es contener (envolver) un objeto de interfaz I.
- "ConcreteDecorator" son las clases D1, D2... que tengamos que implementen la nueva funcionalidad.